
기능 구현 요건
- skill, career 선택된 기준으로 필터링되어야 합니다.
- 모임과 특정 지점간의 거리가 5km 이내 필터링 해야합니다.
- 모임과 특정 지점간의 거리 기준 오름차순 정렬해야 합니다.
해결 1 : 비정규화
비정규화의 필요성
현재 모잇 서비스는 각 모임별 기술 스택 태그, 경력 태그를 등록할 수 있습니다.
등록된 태그를 기준으로 메인화면에서 기술 태그, 경력태그가 포함된 모임을 필터링해 조회할 수 있습니다.
기존의 ERD 는 meeting 테이블과 Skill, Career 를 연결한 중간테이블인 MeetingSkill, MeetingCareer 를 생성하여 연관관계를 설정하였습니다.
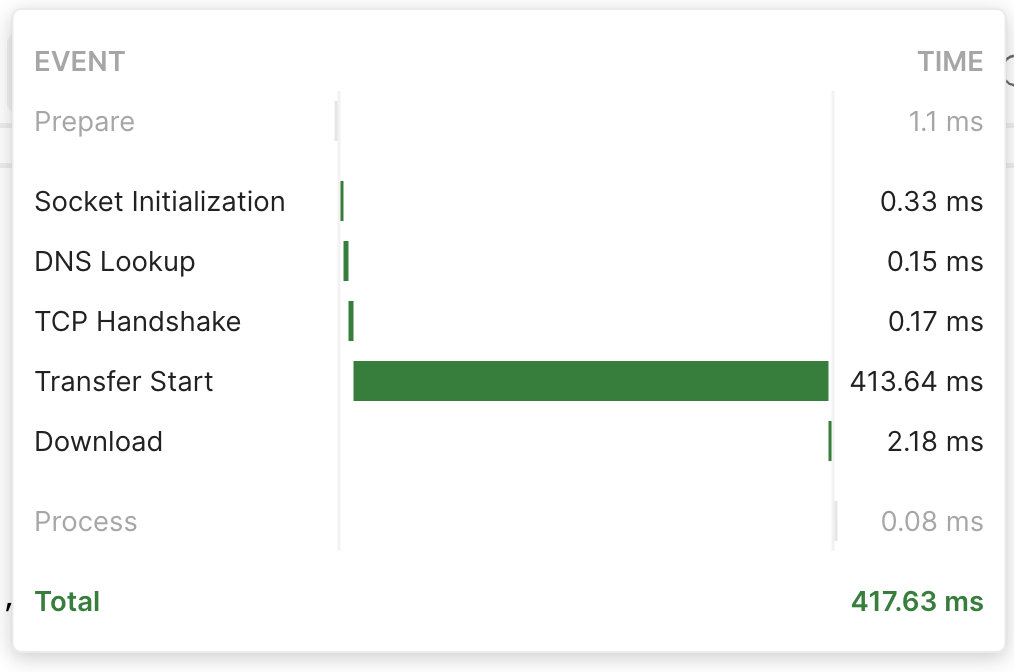
문제 상황
- 대상 테이블(50,185 rows) 413.64 ms
원인
- 2개의 테이블을 JOIN 으로 인해 쿼리 속도 저하됨
- Join 을 위한 Hash 테이블을 생성하고 탐색하기 때문에 속도 저하 발생하는 것으로 추정
비정규화 vs 정규화
- 장점
- Join 횟수를 줄여, 읽기 성능 향상
- query 를 간단하게 변경 가능
- 단점
- DB 저장공간 증대
- 데이터 불일치 발생할 가능성이 있음
- 쓰기(update, insert) 성능 악화
- 결론
- 읽기 >>> 쓰기 : 서비스 특성 상 모임 조회가 모임 생성보다 빈번해, 조회 성능의 향상 중요하다고 판단했습니다.
- 데이터 불일치 발생 가능성 낮음 : 기술 스택, 경력 등의 ID, name 정보는 한번 결정된 후 변경이 없어 meeting에 저장된 기술 스택 리스트나 경력 리스트의 id 나 name 마스터 테이블의 정보와 다를 가능성이 낮음
해결 방법
- MeetingSkill, MeetingCareer 과의 연관관계를 제거후, 비정규화하여 skill, career 에 대한 정보를 칼럼 에 저장하기로 하였습니다.
효과
- 413.64 ms → 192.57 ms 조회 속도
53%개선
ERD(정규화 version)

Query(정규화 version)
```sql
EXPLAIN
SELECT DISTINCT m.*
, ST_Distance( CAST (ST_SetSRID(ST_MakePoint(127.5, 37), 4326) AS geography), m.location_position) AS dist
FROM meeting m
JOIN meeting_skill ms ON m.id = ms.meeting_id
JOIN meeting_career mc ON m.id = mc.meeting_id
WHERE st_dwithin(m.location_position, CAST (ST_SetSRID(ST_MakePoint(127.5, 37), 4326) AS geography), 5000)
AND m.status <> 'DELETE'
AND m.status <> 'COMPLETE'
ORDER BY dist
LIMIT 10
;
```Query Plan(정규화 version)
Limit (cost=381284.46..381286.16 rows=5 width=242) -> Unique (cost=381284.46..381286.16 rows=5 width=242) -> Gather Merge (cost=381284.46..381285.88 rows=5 width=242) Workers Planned: 1 -> Unique (cost=380284.45..380285.31 rows=5 width=242) -> Sort (cost=380284.45..380284.48 rows=15 width=242) " Sort Key: (st_distance('0101000020E61000000000000000E05F400000000000804240'::geography, m.location_position, true)), m.budget, m.location_lat, m.location_lng, m.meeting_date, m.registered_count, m.total_count, m.created_at, m.id, m.meeting_end_time, m.meeting_start_time, m.member_id, m.modified_at, m.contents, m.location_address, m.meeting_name, m.region_first_name, m.region_second_name, m.status, m.career_list, m.skill_list, m.location_position" -> Hash Join (cost=6800.32..380284.15 rows=15 width=242) Hash Cond: (m.id = ms.meeting_id) -> Hash Join (cost=2535.90..375832.05 rows=5 width=242) Hash Cond: (m.id = mc.meeting_id) -> Parallel Index Scan using meeting_pkey on meeting m (cost=0.29..373296.38 rows=3 width=234) " Filter: (((status)::text <> 'DELETE'::text) AND ((status)::text <> 'COMPLETE'::text) AND st_dwithin(location_position, '0101000020E61000000000000000E05F400000000000804240'::geography, '5000'::double precision, true))" -> Hash (cost=1438.05..1438.05 rows=87805 width=8) -> Seq Scan on meeting_career mc (cost=0.00..1438.05 rows=87805 width=8) -> Hash (cost=2418.63..2418.63 rows=147663 width=8) -> Seq Scan on meeting_skill ms (cost=0.00..2418.63 rows=147663 width=8) JIT: Functions: 22 " Options: Inlining false, Optimization false, Expressions true, Deforming true"
Query (비정규화 version)
SELECT m.*, ST_Distance( CAST (ST_SetSRID(ST_MakePoint(127.5, 37), 4326) AS geography), m.location_position) AS dist FROM meeting m WHERE ST_Dwithin( CAST (ST_SetSRID(ST_MakePoint(127.5, 37), 4326) AS geography), m.location_position, 5000) AND ( NULL IS NULL OR EXISTS ( SELECT 1 FROM jsonb_array_elements(m.skill_list) AS skill_json WHERE CAST(skill_json->>'skillId' AS TEXT) = ANY(string_to_array(NULL, ',')) ) ) AND ( NULL IS NULL OR EXISTS ( SELECT 1 FROM jsonb_array_elements(m.career_list) AS career_json WHERE CAST(career_json->>'careerId' AS TEXT) = ANY(string_to_array(NULL, ',')) ) ) AND m.status <> 'DELETE' AND m.status <> 'COMPLETE' ORDER BY dist asc LIMIT 10 OFFSET 0 ;Query Plan(비 정규화 version)
Limit (cost=372943.70..372944.04 rows=3 width=242) -> Gather Merge (cost=372943.70..372944.04 rows=3 width=242) Workers Planned: 1 -> Sort (cost=371943.69..371943.69 rows=3 width=242) " Sort Key: (st_distance('0101000020E61000000000000000E05F400000000000804240'::geography, location_position, true))" -> Parallel Seq Scan on meeting m (cost=0.00..371943.66 rows=3 width=242) " Filter: (((status)::text <> 'DELETE'::text) AND ((status)::text <> 'COMPLETE'::text) AND st_dwithin('0101000020E61000000000000000E05F400000000000804240'::geography, location_position, '5000'::double precision, true))" JIT: Functions: 6 " Options: Inlining false, Optimization false, Expressions true, Deforming true"
해결 2 : GiST 기반의 indexing
위치 칼럼 인덱싱
현재 모잇 서비스는 범위 질의를 하고 있습니다.
사용자가 요청한 지점에서 반경 5km 내에 위치한 모임만을 반환하고 있습니다.
필터링된 모임들을 거리순으로 정렬하여 반환합니다.
원인
- 사용자가 요청한 지점과 모임과의 거리를 계산하는 조건문으로, filtering 하는 데에 가장 많은 비용을 쓰고 있음
- 쿼리 플랜 상 filtering 비용 전체 비용 대비
99.7 %(371943.66 / 372944.04) 차지했습니다. - 반경 5km 내 모임을 연산하는
ST_Dwithinbottleneck 이라고 판단했습니다.
WHERE
ST_Dwithin( CAST (ST_SetSRID(ST_MakePoint(127.5, 37), 4326) AS geography), m.location_position, 5000)해결
- 모임의 위치를 나타내는 location_position 칼럼에 index 를 적용하였습니다.
CREATE INDEX idx_location_position ON meeting USING GiST (location_position);indexing 적용 전 query plan
Limit (cost=266589.03..266589.03 rows=1 width=535) -> Sort (cost=266589.03..266589.03 rows=1 width=535) " Sort Key: (st_distance('0101000020E61000000000000000E05F400000000000804240'::geography, location_position, true))" -> Gather (cost=1000.00..266589.02 rows=1 width=535) Workers Planned: 2 -> Parallel Seq Scan on meeting m (cost=0.00..265588.92 rows=1 width=535) " Filter: (((status)::text <> 'DELETE'::text) AND ((status)::text <> 'COMPLETE'::text) AND ((skill_id_list && '{1,2}'::bigint[]) OR (career_id_list && '{1,2}'::bigint[])) AND st_dwithin('0101000020E61000000000000000E05F400000000000804240'::geography, location_position, '5000'::double precision, true))" JIT: Functions: 6 " Options: Inlining false, Optimization false, Expressions true, Deforming true"indexing 적용후 query plan
Limit (cost=488.59..488.59 rows=1 width=535) -> Sort (cost=488.59..488.59 rows=1 width=535) " Sort Key: (st_distance('0101000020E61000000000000000E05F400000000000804240'::geography, location_position, true))" -> Bitmap Heap Scan on meeting m (cost=4.62..488.58 rows=1 width=535) " Filter: (((status)::text <> 'DELETE'::text) AND ((status)::text <> 'COMPLETE'::text) AND ((skill_id_list && '{1,2}'::bigint[]) OR (career_id_list && '{1,2}'::bigint[])) AND st_dwithin('0101000020E61000000000000000E05F400000000000804240'::geography, location_position, '5000'::double precision, true))" -> Bitmap Index Scan on idx_meeting_location_position (cost=0.00..4.62 rows=29 width=0) " Index Cond: (location_position && _st_expand('0101000020E61000000000000000E05F400000000000804240'::geography, '5000'::double precision))"
효과
- API 속도 97% 단축 (143 ms → 4.5ms)
API 평균 응답 속도(ms)
| 인덱스 O | 인덱스 X | |
|---|---|---|
| 비정규화 JSON | 148 | 4.5 |
해결 3 : 비정규화 방식 변경 (JSON → ARRAY)
현재 상황
경력, 기술스택 필터링 시 ID 로 검색하고 있습니다.
원인
현재 비정규화를 하는 방식은 skill, career 정보를 json 으로 구성되어 json 내의 id가 일치하는지를 검색하게 되어, 검색 비용을 높이고 있습니다.
JSON vs ARRAY
JSON
json (id, name)으로 저장
json (id, name)으로 반환
career_list 예시
[ {"careerId": 1, "careerName": "신입"} , {"careerId": 2, "careerName": "주니어(1~3)"} ]장점 : 반환 시에 별 다른 conversion 과정 없이 기술 스택, 경력과 관련된 정보를 반환할 수 있다.
단점 : 필터링 시 리스트 내의 json 의 key 값을 기준으로 검색하기 때문에, 검색 비용이 크다. jsonb 용량이 integer[] 용량보다 더 크다.
ARRAY
id 배열로 저장
id 배열 → mapper 활용 → json(id, name) 으로 매핑 후 반환
career_id_list 예시
{1,2}장점 : 필터링 시 integer[] 배열의 id 값을 기준으로만 검색하여, jsonb 내의 id 값을 비교하는 것보다 검색 비용이 작다. integer[] 용량이 jsonb 보다 작다.
단점 : 기술 스택, 경력과 관련된 정보를 json으로 반환해야하기 때문에 별도의 mapper 를 생성. 백엔드에서 매핑 과정을 거쳐야 한다.
결론
- JSON을 검색하는 시간보다 backend 에서 array 검색 후 json 으로 변형하는 시간이 더 짧다면 array 로 저장 하는 것이 더 유리하다고 판단했다.
해결 방법
- jsonb 칼럼 대신 id 값만 배열로 저장하는 칼럼을 추가하였다.
- 해당 칼럼의 id 값을 기준으로 json 을 반환하는 SkillMapper, CareerMapper 생성하였다.
효과
- API 응답 평균 속도 5ms → 4ms 감소
| 인덱스 X | 인덱스 O | |
|---|---|---|
| 비정규화 json | 5 | 289 |
| 비정규화 array | 4 | 148.6 |
최종 API 테스트 요약
정규화, 비정규화 3가지 방법
정규화, JSON 방식으로 비정규화, ARRAY 방식으로 비정규화 3가지 방법으로 meeting 테이블의 구조를 다르게 하여 테스트 하였다.
- 정규화 : meeting, meeting_skill, meeting_career 조인 후 반환
- 비정규화 json : meeting 테이블 skill_list, career_list 칼럼 추가
- 비정규화 array : meeting 테이블 skill_id_list, career_id_list 추가
Indexing 여부 2가지 case
location_position 의 GiST index 적용 여부
Skill, Career 필터가 없는 경우
- API URL : http://localhost:8081/api/meetings?&locationLng=127.5&page=1&locationLat=37
- Case 별 1000회 요청 평균 응답속도(ms) 비교
Skill, Career 필터가 있는 경우
- API URL : http://localhost:8081/api/meetings?skillId=1&skillId=2&careerId=1&careerId=2&locationLng=127.5&page=1&locationLat=37
- Case 별 1000회 요청 평균 응답속도(ms) 비교

결론
- 비정규화 적용 후 평균 응답속도는 63.4 % 개선되었습니다.
- Indexing 적용 후 평균 응답속도는 97.31% 개선되었습니다.
- 최종적으로 평균 응답속도는 99% 개선되었습니다.
댓글